Projet de programmation 1: compilateur de C--
Jean Goubault-Larrecq
| LSV/UMR 8643, CNRS, ENS Cachan & INRIA Futurs projet SECSI |
| 61 avenue du président-Wilson, F-94235 Cachan Cedex |
| goubault@lsv.ens-cachan.fr |
| Phone: +33-1 47 40 75 68 Fax: +33-1 47 40 75 21 |
|
1 Introduction
Le cours de programmation s'étend tout au long de la 1ère année à
Cachan. Vous aurez à y faire plusieurs projets. Le tout premier
d'entre eux commence le mardi 27 septembre 2005, et est à rendre le
vendredi 14 octobre 2005.
Il s'agit d'écrire un compilateur pour un sous-ensemble strict du
langage C, que nous appellerons C--. Le langage cible sera
l'assembleur x86. Votre compilateur sera écrit en
OCaml.
Voici un exemple de programme que votre compilateur devrait compiler:

Ce programme, qui sera un de nos exemples le premier jour de cours
(vendredi 30 septembre 2005) code la commande Unix cat.
Au passage, j'ai évidemment fait le projet avant vous. Voici ce que
mon compilateur produit:
.globl main
.type main,@function
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
subl $4, %esp
movl $0x1, %eax
pushl %eax
movl (%esp), %eax
movl %eax, 0x-4(%ebp)
jmp .label_1
.label_1:
movl 0x-4(%ebp), %eax
pushl %eax
movl 0x8(%ebp), %eax
pushl %eax
popl %ebx
popl %eax
cmp %ebx, %eax
jl .label_2
movl $0x0, %eax
jmp .label_3
.label_2:
movl $0x1, %eax
.label_3:
pushl %eax
popl %eax
cmp $0x0, %eax
jne .label_4
jmp .label_5
.label_4:
subl $4, %esp
movl $.label_6, %eax
pushl %eax
movl 0xc(%ebp), %eax
pushl %eax
movl 0x-4(%ebp), %eax
pushl %eax
popl %ebx
popl %eax
movl (%eax, %ebx, 4), %ecx
pushl %ecx
call fopen
addl $0x8, %esp
movl (%esp), %eax
movl %eax, 0x-1-4(%ebp)
jmp .label_7
.label_7:
movl 0x-1-4(%ebp), %eax
pushl %eax
call fgetc
addl $0x4, %esp
movl (%esp), %eax
movl %eax, 0x-8(%ebp)
movl $0x1, %eax
pushl %eax
popl %eax
negl %eax
pushl %eax
popl %ebx
popl %eax
cmp %ebx, %eax
je .label_8
movl $0x0, %eax
jmp .label_9
.label_8:
movl $0x1, %eax
.label_9:
pushl %eax
popl %eax
cmp $0x0, %eax
jne .label_10
movl $0x1, %eax
pushl %eax
jmp .label_11
.label_10:
movl $0x0, %eax
pushl %eax
.label_11:
popl %eax
cmp $0x0, %eax
jne .label_12
jmp .label_13
.label_12:
push stdout
movl 0x-8(%ebp), %eax
pushl %eax
call fputc
addl $0x8, %esp
jmp .label_7
.label_13:
movl 0x-1-4(%ebp), %eax
pushl %eax
call fclose
addl $0x4, %esp
movl 0x-4(%ebp), %eax
pushl %eax
movl (%esp), %eax
addl $0x1, %eax
movl %eax, 0x-4(%ebp)
jmp .label_1
.label_5:
push stdout
call fflush
addl $0x4, %esp
movl $0x0, %eax
pushl %eax
call exit
addl $0x4, %esp
.label_6:
.string "r"
.align 4
Ceci peut vous sembler bien mystérieux. C'est normal! Ça le sera
moins après le premier cours.
2 Comment ça se passe
D'abord, je vous recommande de travailler sous Linux. N'importe
quelle version devrait faire l'affaire. Toutes les versions de Caml
ou OCaml ≥ 2.04 devraient aussi faire l'affaire. Si vous voulez
travailler sur un autre système d'exploitation (Windows par exemple),
c'est votre choix. Sachez cependant que, même avec Cygwin sous
Windows, vous vous exposez à des complications. Allez-y si vous avez
une âme de hacker.
Ensuite, vous devez récupérer
l'archive
du projet. Décompressez-là avec gunzip et désarchivez le
tout avec tar. Vous pouvez faire le tout en une seule étape en
tapant tar -xvzf projet.tgz.
Vous devriez obtenir un répertoire MiniC et
les fichiers suivants:
drwxr-xr-x goubault/lsv 0 2005-09-26 17:57:13 ProjetMiniC/
-rw-r--r-- goubault/lsv 1041 2005-10-07 11:15:35 ProjetMiniC/genlab.ml
-rw-r--r-- goubault/lsv 396 2005-09-26 17:56:08 ProjetMiniC/cat.c
-rw-r--r-- goubault/lsv 12949 2005-10-07 11:15:35 ProjetMiniC/clex.mll
-rw-r--r-- goubault/lsv 2198 2005-10-07 11:15:35 ProjetMiniC/main.ml
-rw-r--r-- goubault/lsv 226254 2005-10-07 11:15:35 ProjetMiniC/clex.ml
-rw-r--r-- goubault/lsv 936 2005-10-07 11:15:35 ProjetMiniC/verbose.ml
-rw-r--r-- goubault/lsv 2752 2005-10-07 11:15:35 ProjetMiniC/error.ml
-rw-r--r-- goubault/lsv 12910 2005-10-07 11:15:35 ProjetMiniC/ctab.mly
drwxr-xr-x goubault/lsv 0 2005-10-07 11:15:36 ProjetMiniC/Exemples/
-rw-r--r-- goubault/lsv 459 2005-10-07 11:15:36 ProjetMiniC/Exemples/cat.c
-rw-r--r-- goubault/lsv 1308 2005-10-07 11:15:36 ProjetMiniC/Exemples/cat.s
-rw-r--r-- goubault/lsv 739 2005-10-07 11:15:36 ProjetMiniC/Exemples/fact.c
-rw-r--r-- goubault/lsv 7256 2005-10-07 11:15:36 ProjetMiniC/Exemples/sieve.s
-rw-r--r-- goubault/lsv 2064 2005-10-07 11:15:36 ProjetMiniC/Exemples/sieve.c
-rw-r--r-- goubault/lsv 2425 2005-10-07 11:15:36 ProjetMiniC/Exemples/fact.s
-rw-r--r-- goubault/lsv 1214 2005-10-07 11:15:35 ProjetMiniC/ctab.mli
-rw-r--r-- goubault/lsv 9081 2005-10-07 11:15:35 ProjetMiniC/cparse.ml
-rw-r--r-- goubault/lsv 521 2005-10-07 11:15:35 ProjetMiniC/depend
-rw-r--r-- goubault/lsv 981 2005-10-07 11:15:35 ProjetMiniC/compile.mli
-rw-r--r-- goubault/lsv 52296 2005-10-07 11:15:35 ProjetMiniC/ctab.ml
-rw-r--r-- goubault/lsv 1849 2005-10-07 11:15:35 ProjetMiniC/Makefile
Votre travail consiste à écrire le fichier manquant
compile.ml. Vous pouvez y écrire ce que
vous voulez, l'important est de définir la fonction dont le type est
spécifié dans le fichier d'interface
compile.mli:
val compile : out_channel -> Cparse.var_declaration list -> unit;;
Cette fonction prend un canal de sortie en premier argument,
appelons-le out, et un programme C--,
appelons-le π, et imprime sur out un texte
en assembleur x86 qui code le programme π. Ce texte en assembleur
ressemblera donc au texte de l'introduction (voir le fichier
cat.s).
Lorsque vous aurez écrit le fichier
compile.mli, compilez le tout en invoquant
make. Comme vous l'aura sûrement expliqué
Sébastien, ceci va appliquer un certain nombre de commandes dans un
ordre défini par les dépendances exprimées dans le fichier
Makefile.
Le résultat sera un programme, qui s'appellera
mcc et sera dans le répertoire
ProjetMiniC. Vous pourrez tester ce
programme en tapant ./mcc
suivi du nom d'un fichier C-- à compiler.
Par exemple, si vous tapez (en partant du répertoire
ProjetMiniC):
cd Exemples
../mcc cat.c
Ceci devrait produire un fichier assembleur
cat.s, que vous pourrez consulter, et un
fichier exécutable cat, que vous pourrez
tester en tapant (sous le répertoire
ProjetMiniC/Exemples):
./cat cat.s
Il est évidemment plus que probable que le code assembleur que vous
produisiez, au moins au début, ne soit pas de la meilleure qualité.
Notamment, mcc appelle le compilateur
gcc pour compiler le code assembleur que
vous aurez produit vers un vrai exécutable. Si votre code assembleur
n'est pas syntaxiquement correct, ceci échouera. Il se peut aussi que
vous obteniez un exécutable, mais qu'il plante (message
Segmentation fault, typiquement).
Dans tous les cas, vous pouvez:
-
Limiter
mcc à ne produire que le code
assembleur, sans le compiler. Appelez-le avec l'option
-E:
../mcc -E cat.c
Ceci affichera le code que votre fonction
compile produit. Vous pouvez envoyer ce
code dans un fichier, disons cat.s encore
une fois, par:
../mcc -E cat.c >cat.s
- Ou bien, et ceci si votre exécutable plante, utiliser le
débogueur graphique
ddd. Si vous ne
l'avez pas, rabattez-vous sur xxgdb, ou
dans le pire des cas sur gdb. Utilisez
les commandes
-
Menu “Data”, item “Status Displays...”, cliquez sur “List
of integer registers and their contents” (pas “List of all
registers...”!), puis “Close” sous
ddd pour voir le contenu des registres
de la machine. Sous gdb, tapez
info registers pour le même effet (en moins beau).
- Menu “Data”, item “Memory...”, tapez sur disons 32
dans la case “View”, puis cochez “hex”, “words”, et
l'adresse mémoire à laquelle vous voulez regardez dans la case
“from”. Par exemple, si
%esp vaut 0xbffff8e0,
tapez 0xbffff8d0 dans le champ “from” pour voir un peu de
part et d'autre de 0xbffff8e0. Sous
gdb, vous obtiendrez le même effet (en
moins beau) avec l'incantation:
x/32xw 0xbffff8d0
3 Quelques règles du jeu
Vous pouvez allez regarder les fichiers que vous voulez. Le seul
fichier que vous n'aurez pas est celui que vous avez à écrire,
compile.ml.
Vous n'avez le droit de modifier aucun des fichiers de
l'archive
du projet. En fait, vous devrez vous limiter à écrire vos
fonctions dans le fichier compile.ml. L'idée,
c'est que si je prends votre fichier compile.ml
et je l'ajoute à l'archive, que je tape
make, j'obtiens un compilateur fonctionnel
pour C--.
Une autre façon de le dire: vous pouvez aller bidouiller les autres
fichiers du projet si ça vous chante, par exemple, pour ajouter des
appels à Printf.printf, et voir comment ça
marche, mais vous ne devez pas faire des modifications dans ces
fichiers qui soit essentielles à la bonne marche de votre compilateur.
4 L'architecture de mcc
D'abord, quand on exécute mcc, il va
commencer par exécuter le code qui se trouve dans le fichier
main.ml.
Celui-ci lit les options de commande (-E par
exemple), puis appelle l'analyseur syntaxique
Ctab.translation_unit, auquel on passe
l'analyseur lexical Clex.ctoken.
Le source de l'analyseur syntaxique, qui servira aussi de
documentation pour la grammaire du langage C--, est dans le fichier
ctab.mly. La description des
tokens lexicaux est dans clex.mll.
L'analyseur syntaxique fournit un programme sous forme d'une liste de
Cparse.var_declaration. Les d'une liste de
var_declaration sont déclarées au début du
fichier cparse.ml, comme suit:
type mon_op = M_MINUS | M_NOT | M_POST_INC | M_POST_DEC | M_PRE_INC | M_PRE_DEC
(* Les operations unaires:
M_MINUS: calcule l'oppose -e de e;
M_NOT: calcule la negation logique ~e de e;
M_POST_INC: post-incrementation e++;
M_POST_DEC: post-decrementation e--;
M_PRE_INC: pre-incrementation ++e;
M_PRE_DEC: pre-decrementation --e.
*)
type bin_op = S_MUL | S_DIV | S_MOD | S_ADD | S_SUB | S_INDEX
(* Les operations binaires:
S_MUL: multiplication entiere;
S_DIV: division entiere (quotient);
S_MOD: division entiere (reste);
S_ADD: addition entiere;
S_SUB: soustraction entiere;
S_INDEX: acces \`a un element de tableau a[i].
*)
type cmp_op = C_LT | C_LE | C_EQ
(* Les operations de comparaison:
C_LT (less than): <;
C_LE (less than or equal to): <=;
C_EQ (equal): ==.
*)
type loc_expr = locator * expr
and expr = VAR of string (* une variable --- toujours de type int. *)
| CST of int (* une constante entiere. *)
| STRING of string (* une constante chaine. *)
| SET_VAR of string * loc_expr (* affectation x=e. *)
| SET_ARRAY of string * loc_expr * loc_expr (* affectation x[e]=e'. *)
| CALL of string * loc_expr list (* appel de fonction f(e1,...,en) *)
(* operations arithmetiques: *)
| OP1 of mon_op * loc_expr (* OP1(mop, e) denote -e, ~e, e++, e--, ++e, ou --e. *)
| OP2 of bin_op * loc_expr * loc_expr (* OP2(bop,e,e') denote e*e', e/e', e%e',
e+e', e-e', ou e[e']. *)
| CMP of cmp_op * loc_expr * loc_expr (* CMP(cop,e,e') vaut e<e', e<=e', ou e==e' *)
| EIF of loc_expr * loc_expr * loc_expr (* EIF(e1,e2,e3) est e1?e2:e3 *)
| ESEQ of loc_expr list (* e1, ..., en [sequence, analogue a e1;e2 au niveau code];
si n=0, represente skip. *)
type var_declaration =
CDECL of locator * string (* declaration de variable de type int. *)
| CFUN of locator * string * var_declaration list * loc_code
(* fonction avec ses arguments, et son code. *)
and loc_code = locator * code
and code =
CBLOCK of var_declaration list * loc_code list (* { declarations; code; } *)
| CEXPR of loc_expr (* une expression e; vue comme instruction. *)
| CIF of loc_expr * loc_code * loc_code (* if (e) c1; else c2; *)
| CWHILE of loc_expr * loc_code (* while (e) c1; *)
| CRETURN of loc_expr option (* return; ou return (e); *)
Le type locator est juste un pointeur sur des
informations permettant aux fonctions
Error.error et
Error.warning d'afficher des message d'erreur
sensés.
Le fichier cparse.ml contient aussi des
fonctions utiles, comme string_of_loc_expr,
qui vous permettent d'obtenir une version imprimable d'une expression
C--, ce que vous pouvez utiliser en phase de débogage.
Le fichier genlab.ml contient une fonction
genlab qui vous permettra de fabriquer des labels uniques,
ce qui devrait être bien pratique lorsque vous émettrez des
instructions de saut dans votre code assembleur.
Le fichier verbose.ml déclare une variable
verbose que vous pourrez tester pour régler
le niveau d'informations de débogage que vous voudrez afficher (elle
vaut 1 si vous appelez mcc avec l'option
-v1, 2 si avec l'option
-v2, et 0 par défaut).
5 Le langage C--
C-- est un sous-ensemble extrêmement réduit du langage C. Ont été
supprimés de C: tous les types struct,
union, enum, ainsi que
les tableaux, et la plupart des types scalaires. En fait, il ne reste
que les types int,
char *, et les pointeurs sur les types C-- (récursivement).
L'avantage est que tous ces types tiennent sur 32 bits. Vous n'aurez
donc pas à vous casser la tête pour savoir combien de place allouer à
chaque variable: ce sera toujours 4 octets.
Ensuite, de nombreuses constructions de C ont été supprimées, mais pas
suffisamment pour ne pas pouvoir compiler des programmes intéressants.
En principe, C-- est un sous-ensemble de C, ce qui signifie que vous
pourrez tester mcc en comparant les
programmes qu'il produit avec ceux produits par
gcc.
Il n'y a qu'une exception à ce principe: l'arithmétique sur les
pointeurs a une sémantique différente en C-- et en C. Si vous
déclarez int *p et écrivez
p++ en C, ceci ajoute
sizeof(int), soit 4, à l'adresse
p. En C–, ça n'est censé qu'ajouter un. Je
doute que vous ayez à considérer ce genre de subtilités, mais qui
sait.
6 La sémantique opérationnelle à grands pas de C--
Soit Z32 l'ensemble de tous les entiers signés 32 bits: Z32 =
[−231, 231−1]. Soit Addr le sous-ensemble de toutes les
adresses.
Nous allons présenter la sémantique de C-- en deux étapes. En
section 6.1, nous présenterons une sémantique pour un
sous-ensemble extrêmement réduit de C--. L'avantage est que cette
sémantique sera très simple. Certaines particularités de C-- nous
forceront à décrire une sémantique plus compliquée en
section 6.2.
6.1 Une sémantique simple pour un sous-ensemble de C--
Considérons un langage où les expressions sont juste celles de la
forme:
|
|
| e |
::= |
x |
variable |
| |
| |
e plus e |
addition |
| |
| |
call f (e, …, e) |
appel de fonction |
|
|
|
| c |
::= |
x=e |
affectation |
| |
| |
skip |
ne rien faire |
| |
| |
c;c |
séquence |
| |
| |
if (e) then c else c |
test |
| |
| |
while (e) c |
boucle |
|
Les expressions et les instructions seront évaluées dans un environnement ρ, qui est une fonction de domaine fini associant
une valeur dans Z32 à des variables.
Définissons des règles permettant de déduire des jugements de
la forme ρ ⊢πe ⇒ V, signifiant “dans l'environnement ρ,
l'expression e a pour valeur V”.
On a d'abord une règle pour la variable:
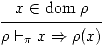
(1)
Cette règle s'applique dès que x est dans le domaine de ρ. Elle
n'a aucune (autre) prémisse.
On a ensuite une règle pour l'addition:
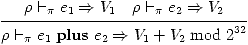
(2)
(La raison pour laquelle nous écrivons l'addition
e1 plus e2 plutôt que e1+e2 par exemple est pour
bien distinguer l'opération syntaxique plus de l'opération
mathématique d'addition, notée +.)
Nous traiterons de l'appel de fonctions plus loin.
On peut maintenant définir des jugements de la forme ρ ⊢πc ⇒ ρ'
pour chaque instruction c, signifiant “en partant de
l'environnement ρ, l'instruction c termine sur un nouvel
environnement ρ', le programme courant étant π”. De nouveau, les
jugements dérivables sont définis par des règles de déduction.
La première est pour l'affectation:
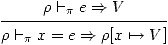
(3)
La notation ρ [x ↦ V] désigne la fonction de domaine dom ρ ∪ {x},
qui à x associe V et à tout y in dom ρ \ {x} associe ρ (y).
L'instruction skip ne fait strictement rien de remarquable:

(4)
La séquence évalue ses arguments... en séquence:

(5)
Elle introduit donc un environnement intermédiaire ρ' représentant
l'environnement après l'exécution de e1 et avant l'exécution de
e2.
Jusqu'ici, nous avions une règle de déduction par construction
syntaxique. Ceci change pour le test. Nous avons une règle lorsque
la condition testée est fausse, et une lorsqu'elle est vraie:
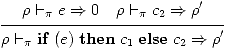
(6)
Comme en C, 0 est faux, et tout autre nombre est considéré comme vrai.

(7)
La boucle while (e) c est équivalente à if
(e) then c;while (e) c
else skip. Ceci donne lieu, ici aussi, à deux
règles pour l'évaluation des boucles.
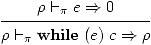
(8)

(9)
La seconde règle a la particularité que sa seconde prémisse ne porte
pas sur une instruction plus petite que celle en conclusion,
contrairement aux règles présentées jusqu'ici. Ceci mène à des
comportements non terminants. Disons que c termine
dans π, à partir de ρ, si et seulement s'il existe ρ' tel que ρ
⊢πc ⇒ ρ' soit déductible.
Exercice 1
Si ρ (x) n'est pas défini, while (x) skip
termine-t-il?
Exercice 2
Montrer que while (x) skip termine à partir de
ρ si et seulement si x in dom ρ et ρ (x) = 0.
L'appel de fonction fait aussi ce qu'on attend de lui:
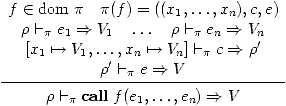
(10)
où [x1↦ V1, …, xn↦ Vn] est l'environnement qui à x1 associe
V1, ..., à xn associe Vn.
Exercice 3
Que se passe-t-il si on appelle une fonction f sur le mauvais
nombre d'arguments, i.e., si on cherche à évaluer call f
(e1, …, en) alors que π (f) = ((x1, …, xm), c) et m ≠ n?
Que se passe-t-il si f ∉dom π?
Exercice 4
Montrer que cette sémantique est déterministe: si ρ ⊢πc ⇒
ρ' et ρ ⊢πc ⇒ ρ'' sont déductibles, alors ρ' = ρ''. Dites
précisément sur quoi vous effectuez une récurrence, et décrivez
quelques-uns des cas que vous traitez, notamment ceux utilisés
lorsque c est une boucle while.
Exercice 5
En Caml, on n'a pas besoin de la construction while. Au
lieu d'écrire:
while e do c;;
on peut en effet écrire
let rec f () =
if e
then begin
c;
f ()
end
else ()
in f ();;
où f est un nom frais (non utilisé dans e ou
c). Peut-on recoder les boucles while par un codage
similaire dans le langage de cette section? Et en C? Et en C--?
Il manque à cette sémantique, notamment, l'allocation mémoire et les
pointeurs, les variables globales, la possibilité d'effectuer des
effets de bord à l'intérieur des expressions. Ceci sera réparé dans
la sémantique de C--, que nous décrivons tout de suite.
6.2 La sémantique de C--
Un programme π est pour nous un couple (ρπ,
funπ):
-
L'environnement global ρπ:
string → Addr envoie chaque nom de
variable globale vers une adresse allouée pour elle. (Les variables
globales sont décrites par les CDECL
(loc,x) dans la liste de var_declaration
fournie à la fonction compile. Le
compilateur doit donc allouer une place mémoire pour chaque.)
- La définition funπ:
string →
var_declaration list ×
loc_code envoie chaque fonction définie
dans le programme vers son code. (Ce sont les
CFUN (loc, f, params, code) dans la liste
de var_declaration fournie à la fonction
compile.)
On supposera pour simplifier que funπ contient aussi des
entrées pour toutes les fonctions de la libc, comme
printf, strcpy, malloc, free, etc. Et
que, de même, ρπ contient aussi des entrées pour toutes les
variables globales de la libc, comme errno par exemple.
Exercice 6
La définition de π permet-elle d'allouer deux variables à la même
adresse? Ceci est-il souhaitable? Si oui, pourquoi? Si non,
comment réparer la définition?
Exercice 7
La définition de funπ n'autorise pas à avoir deux
fonctions de même nom. Mais il peut y avoir deux
CFUN (loc, f, params, code) avec le même
f fourni à la fonction compile. Comment
traduisez-vous ces dernières
var_declaration en entrées pour
funπ, pour tenir compte de cette différence
conceptuelle?
On définit une série de jugements de sémantique opérationnelle de la
forme μ, ρ ⊢πe ⇒ v, μ', qui dit qu'en partant d'une mémoire μ :
Addr → Z32, et d'un environnement ρ :
string → Addr qui dit à quelles adresses
sont stockées les variables, l'expression C-- e peut s'évaluer en
la valeur v in Z32, et modifier la mémoire en μ'.
Il y a deux sortes de variables. Les variables locales (ou
automatiques dans le jargon du C) sont données dans
l'environnement ρ:
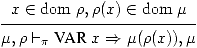
(11)
Les variables globales sont décrites par l'environnement
global ρπ.
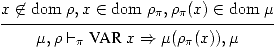
(12)
Exercice 8
Quelle règle s'applique-t-elle dans le cas d'une variable locale
(x in dom ρ) qui a le même nom qu'une variable globale (x in dom
ρπ)?
Exercice 9
Que se passe-t-il si x est une variable globale pour laquelle
aucune mémoire n'est allouée (ρπ(x) ∉dom μ?)

(13)
L'évaluation des chaînes est un peu plus étrange. Elle retourne une
adresse mémoire quelconque où se trouve déjà la représentation de s.
Disons que s est stockée à l'adresse a si et seulement si
s ne contient pas l'octet 0, il existe une adresse a+k dans la
mémoire μ contenant un octet nul, avec k minimal, et la suite de
tous les octets aux adresses a, a+1, a+2, ..., a+k−1 vaut s.
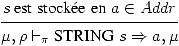
(14)
En pratique, le compilateur devra allouer de la place pour la chaîne
s à la compilation. Ceci est fait pratiquement automatiquement
par l'assembleur. Par exemple,
.main_3:
.string "r"
.align 4
réserve de la place pour les octets `r' et 0, les place à une adresse
nommée .main_3. L'instruction mystérieuse
.align 4 sert à assurer que ce qui suit commencera à une
adresse multiple de 4, ce qui facilite la tâche du processeur pour
certaines opérations.
Exercice 10
La sémantique ci-dessus n'oblige pas à stocker toute chaîne présente
dans le programme. Que se passe-t-il si s n'est stockée nulle
part?
Pour toute mémoire μ, pour toute adresse a in Addr, pour toute
valeur v in Z32, notons μ [a ↦ v] la mémoire qui à a associe
v, et à toute autre adresse a' ≠ a associe μ (a').
On a encore deux règles pour SET_VAR, selon
que la variable est locale ou globale.

(15)

(16)
Exercice 11
Que se passe-t-il si on écrit x=1 en C--
mais que x n'est pas dans dom ρ? ... ni
dans dom ρ ni dans dom ρπ? Ceci arrive lorsque
x n'aura pas été déclarée, typiquement par
int x. Comment réagit
mcc dans ce cas? Comment réagit
gcc dans ce cas?
Exercice 12
Pourquoi demande-t-on ρ (x) in dom μ', resp. ρπ(x) in dom μ'
dans ces règles? Autrement dit, quel genre de comportement étrange
l'omission de ces conditions autoriserait-il?
Passons aux instructions de la forme x[i]=e. On comprend l'addition
a+v comme étant effectuée modulo 232.
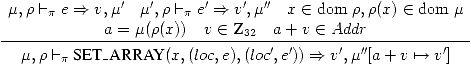
(17)
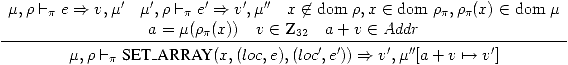
(18)
Exercice 13
Dans quel ordre cette règle évalue-t-elle e et e'? Que spécifie
la norme ANSI C?
Exercice 14
Pourquoi demandons-nous que v in Z32 et a+v in Addr dans ces
règles?
Disons qu'une mémoire μ' étend μ, ce que nous noterons μ'
⊑ μ, si et seulement si dom μ' ⊇ dom μ et μ'|dom μ = μ. On
note [x1 ↦ a1, …, xn ↦ an] la fonction qui à chaque xi
associe ai, 1≤ i≤ n. Ceci est bien défini lorsque les xi sont
distinctes deux à deux.

(19)
Exercice 15
Dans quel ordre sont évalués les arguments d'un appel de fonction
CALL comme ci-dessus? Que dit la norme
ANSI C à ce sujet?
Exercice 16
Pourquoi demande-t-on μ'n ⊑ μn, ..., μ'2 ⊑ μ2, μ'1 ⊑ μ1
dans (19)? Pour répondre à cette question, imaginez
que μ'n=μn, ..., μ'2=μ2 dans (19), et
demandez-vous si votre compilateur produit effectivement du code
correspondant à la spécification.
Exercice 17
Pourquoi, sur le même principe, ne demanderions-nous pas des
mémoires auxiliaires qui étendent μ', plutôt que de réutiliser
directement μ' dans l'évaluation de e', dans les règles
(17) et (18)?
Exercice 18
Que se passe-t-il si la fonction f n'est pas définie? Si f est
définie avec un nombre d'arguments différent de n? Si la liste
des paramètres formels de f n'est pas de la forme
CDECL (l1, x1), …,
CDECL (ln, xn) mais contient un élément
de la forme CFUN (…)?
Exercice 19
Pourquoi demande-t-on a1 ∉dom μ1, ..., an ∉dom μn
dans les prémisses de (19)?
Exercice 20
Rien n'empêche les variables x1, ..., xn d'être non distinctes.
Si c'est le cas, la notation [x1 ↦ a1, …, xn ↦ an] n'a aucun
sens. Réparez la règle (19) pour tenir compte de ce
fait.
Passons aux opérations unaires. La négation effectue son calcul modulo 232.
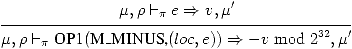
(20)
Exercice 21
Dans quel cas le modulo 232 est-il nécessaire?
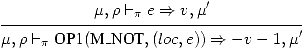
(21)
Exercice 22
On aurait pu s'attendre que la négation bit à bit soit décrite en
termes des bits de v. Montrer que la définition ci-dessus est
équivalente, autrement dit que −v−1 est bit la négation bit à bit
de v.
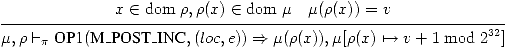
(22)
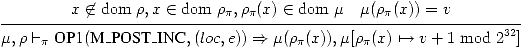
(23)
Exercice 23
Que se passe-t-il si on applique M_POST_INC
à autre chose qu'une variable?
Exercice 24
Écrire les règles sémantiques pour
M_PRE_INC,
M_POST_DEC,
M_PRE_DEC.
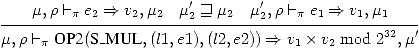
(24)
Exercice 25
Pourquoi μ'2 ⊑ μ2?
Exercice 26
Dans quel ordre sont évalués les arguments?
Exercice 27
Écrire les règles sémantiques pour S_DIV,
S_MOD, S_ADD,
S_SUB.
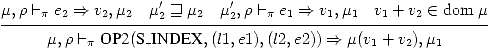
(25)
Exercice 28
Écrire le reste de la sémantique!
7 Guide de référence rapide de l'assembleur x86
Les registres: %eax %ebx %ecx %edx %esi %edi %ebp %esp.
Ils contiennent tous un entier de 32 bits (4 octets), qui peut aussi être vu
comme une adresse. Le registre %esp est spécial, et pointe sur le
sommet de pile; il est modifié par les instructions pushl,
popl, call, ret notamment.
Il y a aussi d'autres registres que l'on ne peut pas manipuler directement.
(L'instruction info registers sous gdb ou ddd vous les
montrera.) Le plus important est eip, le compteur de programme:
il contient en permanence l'adresse de la prochaine instruction à
exécuter.
1em
-
addl <source>, <dest>.......<dest>= <dest>+
<source> (addition)
Ex: addl $1, %eax ajoute 1 au registre %eax.
Ex: addl $4, %esp dépile un élément de 4 octets de la pile.
Ex: addl %eax, (%ebx, %edi, 4) ajoute le contenu de %eax à
la case mémoire à l'adresse %ebx + 4*%edi. (Imaginez
que %ebx est l'adresse de début d'un tableau a, %edi
est un index i, ceci stocke %eax dans a[i].)
andl <source>, <dest>.......<dest>= <dest>& <source> (et
bit à bit)
call <dest>.......appel de procédure à l'adresse <dest>
Équivalent à pushl $a, où a est l'adresse juste
après l'instruction call (l'adresse de retour), suivi de
jmp <dest>.
Ex: call printf appelle la fonction printf.
Ex: call *%eax (appel indirect) appelle la fonction dont l'adresse est dans le
registre %eax. Noter qu'il y a une irrégularité dans la
syntaxe, on écrit call *%eax et non call (%eax).
cltd .......conversion 32 bits -> 64 bits
Convertit le nombre 32 bits dans %eax en un nombre sur 64
bits stocké à cheval entre %edx et %eax.
Note: %eax n'est pas modifié; %edx est mis à 0 si
%eax est positif ou nul, à −1 sinon.
À utiliser notamment avant l'instruction idivl.
cmp <source>, <dest>.......comparaison
Compare les valeurs de <source> et <dest>. Utile juste avant un saut
conditionnel (je, jge, etc.). À noter que la comparaison
est faite dans le sens inverse de celui qu'on attendrait. Par exemple,
cmp <source>, <dest> suivi d'un jge (“jump if greater than or
equal to”), va effectuer le saut si <dest>≥<source>: on compare <dest> à
<source>, et non le contraire.
idivl <dest>.......division entière et reste
Divise le nombre 64 bits stocké en %edx et %eax (cf.
cltd) par le nombre 32 bits <dest>. Retourne le quotient en
%eax, le reste en %edx.
imull <source>, <dest>.......multiplie <dest> par <source>,
résultat dans <dest>
jmp <dest>.......saut inconditionnel: eip=<dest>
je <dest>.......saut conditionnel
Saute à l'adresse <dest> si la comparaison précédente (cf.
cmp) a conclu que <dest>=<source>, continue avec le flot normal du
programme sinon.
jg <dest>.......saut conditionnel
Saute à l'adresse <dest> si la comparaison précédente (cf.
cmp) a conclu que <dest>><source>, continue avec le flot normal du
programme sinon.
jge <dest>.......saut conditionnel
Saute à l'adresse <dest> si la comparaison précédente (cf.
cmp) a conclu que <dest>≥<source>, continue avec le flot normal du
programme sinon.
jl <dest>.......saut conditionnel
Saute à l'adresse <dest> si la comparaison précédente (cf.
cmp) a conclu que <dest><<source>, continue avec le flot normal du
programme sinon.
jle <dest>.......saut conditionnel
Saute à l'adresse <dest> si la comparaison précédente (cf.
cmp) a conclu que <dest>≤<source>, continue avec le flot normal du
programme sinon.
leal <source>, <dest>.......chargement d'adresse effective
Au lieu de charger le contenu de <source> dans <dest>, charge l'adresse de <source>.
Équivalent C: <dest>=&<source>.
movl <source>, <dest>.......transfert
Met le contenu de <source> dans <dest>. Équivalent C: <dest>=<source>.
Ex: movl %esp, %ebp sauvegarde le pointeur de pile %esp dans
le registre %ebp.
Ex: movl %eax, 12(%ebp) stocke le contenu de %eax dans les
quatre octets commençant à %ebp+12.
Ex: movl (%ebx, %edi, 4), %eax lit le contenu de
la case mémoire à l'adresse %ebx + 4*%edi, et le met
dans %eax. (Imaginez
que %ebx est l'adresse de début d'un tableau a, %edi
est un index i, ceci stocke a[i] dans %eax.)
negl <dest>.......<dest>=-<dest>(opposé)
notl <dest>.......<dest>=~<dest>(non bit à bit)
orl <source>, <dest>.......<dest>= <dest>|
<source> (ou bit à bit)
popl <dest>.......dépilement
Dépile un entier 32 bits de la pile et le stocke en <dest>.
Équivalent à movl (%esp),<dest> suivi de
addl $4, %esp.
Ex: popl %ebp récupère une ancienne valeur de %ebp
sauvegardée sur la pile, typiquement, par pushl.
pushl <source>.......empilement
Empile l'entier 32 bits <source> au sommet de la pile.
Équivalent à movl <source>, -4(%esp) suivi de
subl $4, %esp.
Ex: pushl %ebp sauvegarde la valeur de %ebp, qui sera
rechargée plus tard par popl.
Ex: pushl <source> permet aussi d'empiler les arguments successifs
d'une fonction. (Note: pour appeler une fonction C comme printf
par exemple, il faut empiler les arguments en commençant par celui de droite.)
ret .......retour de procédure
Dépile une adresse de retour a, et s'y branche. Lorsque la pile
est remise dans l'état à l'entrée d'une procédure f, ceci a pour
effet de retourner de f et de continuer l'exécution de la procédure
appelante.
Équivalent à popl eip... si cette instruction existait (il n'y
a pas de mode d'adressage permettant de manipuler eip directement).
subl <source>, <dest>.......<dest>= <dest>- <source>(soustraction)
Ex: subl $1, %eax retire 1 du registre %eax.
Ex: subl $4, %esp alloue de la place pour un nouvel élément de
4 octets dans la pile.
xorl <source>, <dest>.......<dest>= <dest>^
<source> (ou exclusif bit à bit)
8 Un dernier mot
Bon courage, et travaillez bien!
N'hésitez pas à nous contacter,
goubault@lsv.ens-cachan.fr
ou bardin@lsv.ens-cachan.fr
This document was translated from LATEX by
HEVEA.